Hi,I am Rupendra
Deep learning / Computer-vision researcher

Deep learning / Computer-vision researcher
How did I learn
Started to work on basic Artificial neural networks (ANN), then moved over to building convolutional neural networks (CNN) with several max-pooling and convolutional layers then worked over several pre-trained machine learning models such as Visual geometry group (VGG16), Single Shot Detector (SSD mobilenetV2), Single Shot Detector (SSD mobilenetV3), Efficientnet0 etc. and also worked with Teachable machine Teachable machine and TensorFlow Lite model maker
How did I learn
Initially, I started to work with the You look only once algorithm (YOLO) and labeled all the images using the LabelImg tool. Every dataset was trained over google colab GPU, but then after exploring the other object detection algorithms, I started to work with the Tensorflow Zoo models but still compared to Tensorflow Zoo models, YOLO has the highest mean average precision (MAP), and my favorite object detection algorithm remains to be YOLO
How did I learn
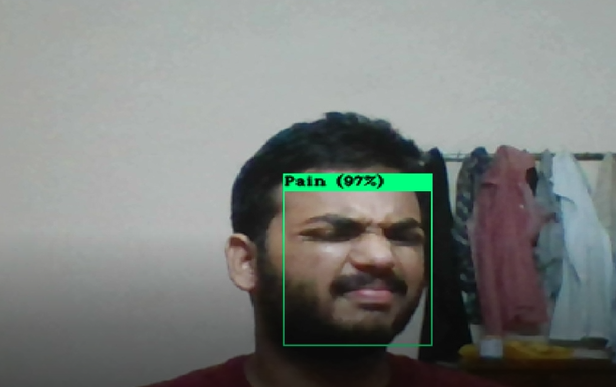
I was very interested in working over the pose detection models, so I initially tried the Open-Pose to detect all body key points. Still, then I was not able to continue my work on it since open pose requires a very high GPU and google colab has some limitations to work with openpose still then I found the Media-Pipe which is developed by Google and can be utilized with CPU, it not only has the pose detection models but also other models such as face mesh, hand detection, face detection, hair segmentation, and many other models, so I used the hand detection model to get all the key points. I tuned the algorithm to select some particular vital points for different projects.
Masters student at Ontario Tech University
I started a master's in computer science (Thesis) at Ontario Tech University in the Fall of 2021. Deeply interested in research and working in the deep learning/computer vision field.
He loves to work with images/videos and make some innovative applications with the help of computer vision, as He sees that this field has a lot of potential in every sector. A good deal of research has to be done in this field.

A selection of my range of work
Note : Please click on below images to view the work in more detail with demo's





IEEE Conference Paper: Jennifer Alejandra Cardenas Castaneda, Rupendra Krishna Raavi, Carolina Padilla Velasco, Marco Antonio Mart´ınez Cano, Robee Kassandra Adajar, Jay Shiro Tashiro, and Patrick C. K. Hung. (2021). Assistive Technology for Visually Impairment: Three Research Initiatives. IEEE. IV International Conference of Inclusive Technology and Education (CONTIE 2021), La Paz, Mexico, Conference Date: 2021/10.
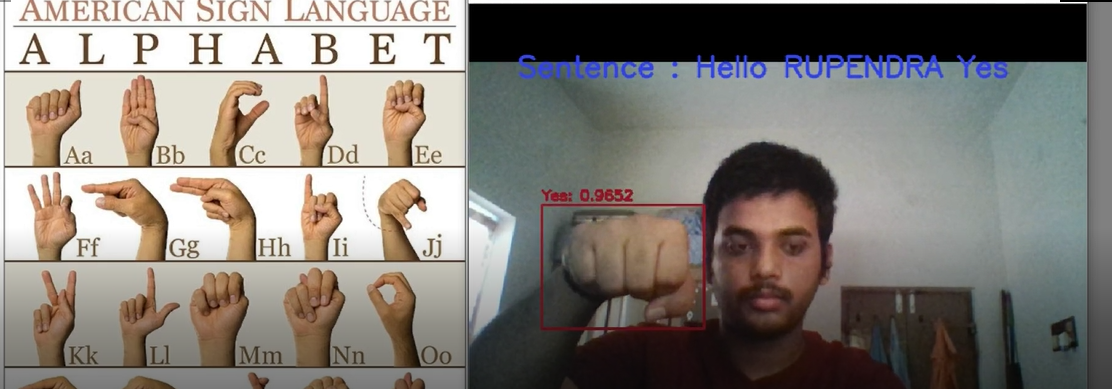
Presentation at Conference of Connecting Dots : I gave a presentation on Sign language recognition, where I spoke about different machine learning models that will be helpful for visually impaired people to communicate.
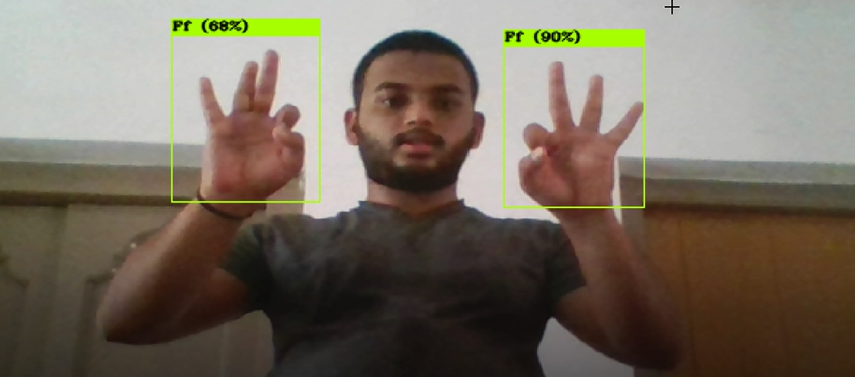
Paper presentation at CONTIE 2021 – Mexico: Presented my part of the above paper, which is American Sign Language Recognition using object detection approach. (Received outstanding presentation certificate).
ISFAR-SU2022 Presentation: Abstract paper is accepted for the 8th International Symposium toward the Future of Advanced Researches in Shizuoka University 2022 and paper is presented on the topic called sign language recogniton using the data gloves.
Springer (Encyclopedia of computer graphics and games): A paper based on the American sign language recognition is peer-reviewed. Minor modifications are suggested by the reviewer.
Springer (Encyclopedia of computer graphics and games): Captcha based on facial recognition is a paper that was recently submitted. It's peer-reviewed but minor modifications are suggested by the reviewer.